阿里发布具身大模型Qwen-Robot系列,三大模型让机器人学会“边走、边看、边思考”

三者分别赋予机器人灵巧操作、自主导航与环境认知能力,既可独立部署,亦可协同运转,让机器人真正实现“边走、边看、边思考”,为不同形态机器人走向真实场景提供可依赖的“通用底座”。
新系列在第三方真机评测中取得领先成绩。在横跨30项真实世界任务、覆盖4个机器人平台的RoboChallenge Table30 v1评测中,Qwen-Robot操作模型的两个版本包揽榜单前两名,所完成的任务涵盖拧水龙头、插网线、双臂倒薯条等高难度操作。值得一提的是,该模型全程仅使用开源数据训练,打破了业内对私有数据采集的普遍依赖。
目前,全球具身智能行业正处于从实验室研发向真实场景商业化跨越的临界点,如何在陌生环境中稳定执行复杂指令,是这一领域商业化落地的核心门槛。Qwen-Robot系列的发布,折射出国内大模型厂商将技术能力向机器人硬件场景延伸的加速趋势。
统一表征让机器人“跨硬件迁移”,相对感知让操作“随机应变”
VLA(Vision-Language-Action,视觉-语言-动作)模型是当前具身智能领域的核心基础模型之一,旨在融合视觉感知、语言理解与动作决策,使机器人具备“看得懂、能动手”的智能。
传统VLA模型的主要瓶颈在于迁移能力不足,更换硬件本体或操作场景后性能往往大幅衰减。此次发布的VLA操作模型Qwen-RobotManip从两个维度破解这一难题。
其一,模型采用一套80维的统一动作表征,为不同硬件平台定义通用的“肢体语言”,使模型学习的是基础物理规律与操作逻辑,而非对特定动作序列的机械记忆。
其二,模型放弃对繁琐绝对坐标的计算依赖,转而基于摄像头画面中的相对位置直接生成操作指令,从而在面对环境变化时实现更快、更准的响应。在新硬件上部署时,模型仅需少量交互反馈即可快速适配,显著降低了跨平台迁移成本。
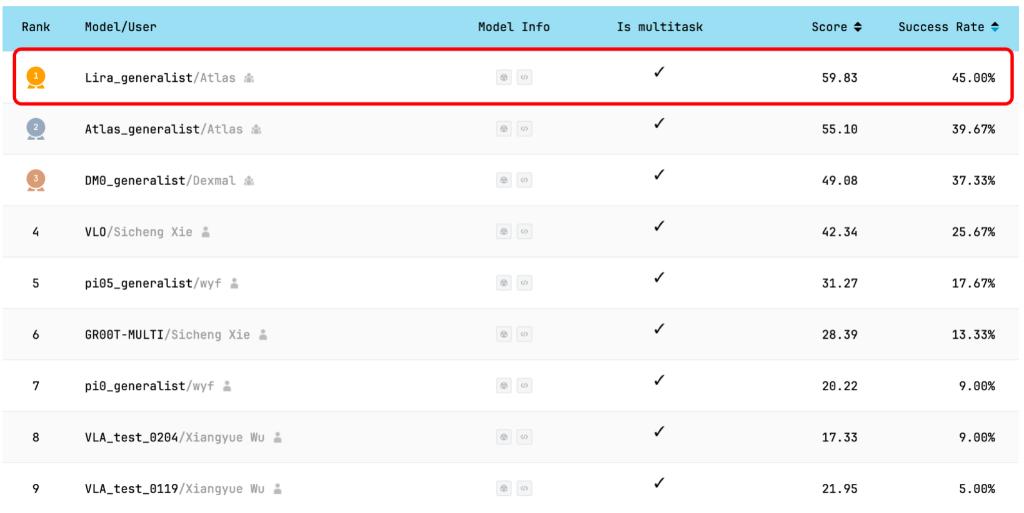
在训练阶段,Qwen-RobotManip完成了超过38000小时的大规模语料预训练。在RoboChallenge真机多任务全球评测中,其以“Lira”和“Atlas”命名的两个版本包揽榜单前两名。
记忆策略自适应,让机器人导航不再“迷路”
如果说操作模型解决的是机器人“如何动手”的问题,那么此次发布的VLN移动导航模型Qwen-RobotNav则聚焦于“如何认路、会跑腿”。
该模型基于Qwen-VL构建,将语言指令导航、目标搜索、自动驾驶等五大任务族统一至同一框架,无需在复杂任务中手动切换模型。
传统VLN模型普遍面临记忆策略僵化的困境——记忆过少容易迷路,记忆过多则导致混乱。Qwen-RobotNav对此引入任务自适应观察机制,可根据任务类型灵活调整记忆策略。
更重要的是,该模型采用通用接口设计,可被上层模型直接调用,是业内少数原生支持多种智能体框架的VLN模型。
理解物理规律、预演动作轨迹,让机器人学会“思考”
Qwen-RobotWorld是Qwen-Robot系列的第三大模型,定位于具身智能世界模型。它基于物理规律认知,能够推理并模拟机器人下一时刻的动作与状态,为真实世界的行动提供预演基础。
该模型有双重价值:一是生成视频数据用于训练,缓解具身智能数据短缺难题;二是在动作执行前预先推演轨迹,提升操作精度与完成质量。
三大模型共同构成千问具身智能体系,在统一语言指令下既可单独部署,也能协同运转,让机器人真正实现“边走、边看、边思考”。
本文来自华尔街见闻,欢迎下载APP查看更多






