过去一年人形机器人掌握了哪些技能,助力普通人应对复杂任务

一台身高1.6米的机器人,在春晚舞台上扭动腰肢,转动手绢,动作流畅得像真人。这不是科幻电影,而是2025年除夕夜的真实画面。与此同时,另一台机器人正以1.6公斤负载跑完百米,还有机器人踢足球、指挥交响乐、走进小学课堂。人形机器人不再只是实验室的展品,它们正在真实世界中“动起来、看懂事、听懂话”。

这一年,机器人不仅跑得更远、动得更灵,更重要的是,它们开始“思考”。北京创新中心的R-WMES系统让机器人能基于“世界模型”自主规划任务;智元机器人的启元大模型在倒水、清理等操作中成功率逼近80%;小鹏的IRON机器人甚至不再需要语言转译,直接从视觉输入生成动作。这些突破背后,是视觉-语言-动作(VLA)模型的全面落地,标志着人形机器人正从“被操控”迈向“能理解”的智能新纪元。

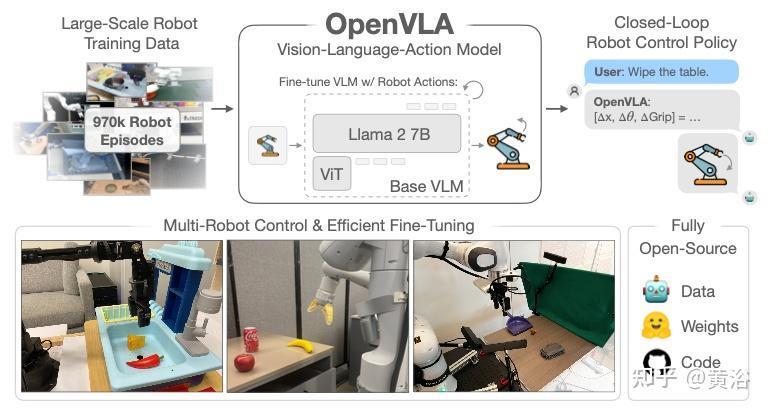
VLA模型的核心,是将视觉、语言与动作统一于一个端到端的神经网络。它不再依赖传统机器人“感知—规划—控制”的割裂流程,而是像人一样:眼睛看到场景,耳朵听懂指令,身体直接做出反应。其技术路径清晰而深刻——首先,DINOv2或SigLIP等视觉编码器将摄像头图像切分为“视觉token”,捕捉空间结构与语义信息;接着,语言指令被嵌入LLM(如LLaMA或Qwen)空间,通过轻量级“投影器”与视觉token对齐;最终,模型以自回归方式生成离散化的动作token,解码为机械臂位移、关节角度或移动轨迹。
这一架构的革命性在于“统一表征”。过去,机器人识别杯子靠CV模型,理解“拿杯子”靠NLP模块,执行动作靠运动规划算法,每个环节都可能出错。而VLA通过大规模预训练,让模型在同一个语义空间中理解“杯子”既是图像中的圆形物体,也是语言中的名词,更是可抓取的物理目标。当指令变为“把红杯子放到架子左边”,模型无需调用多个独立系统,而是直接输出一连串动作指令,误差链被大幅压缩。
有人质疑:这是否只是“数据堆出来的巧合”?但dVLA等新型模型已引入“多模态思维链”——先预测子目标图像,再生成推理文本,最后输出动作。这种“可视化思考”过程,使机器人具备了类人的任务分解能力。清华大学火神队机器人在足球赛中完成定位、射门与庆祝,正是这种能力的体现:它不只是执行代码,而是在“理解比赛”。
更深远的变化在于成本与生态。宇树R1售价3.99万元,松延动力“小布米”跌破万元门槛,北京、上海相继建成具身智能4S店与租赁平台。硬件量产与模型开源(如XR-1)形成正向循环,推动机器人从“企业采购”走向“机构租赁”甚至“个人拥有”。当优必选单笔订单突破2.64亿元,当Ai博士生“学霸01”登上戏曲舞台,我们看到的不仅是技术突破,更是一种新生产力的萌芽。

技术从不孤立前行。VLA的成熟,意味着机器人将不再局限于重复性劳动,而是进入教育、医疗、家庭等复杂场景。未来的工厂里,工人只需说“把这批零件送到质检台”,机器人便能自主判断路径、避障、搬运;在养老院,老人一句“我想喝水”,机器人便能识别情绪、找到水杯、平稳递送。

但真正的智能,不只是“听懂话”,而是“懂人心”。当前VLA仍依赖大量标注数据,泛化能力有限,对模糊指令或文化语境的理解依然薄弱。下一步的突破,将取决于世界模型的完善与因果推理的引入——让机器人不仅能做眼前的事,还能预判后果、权衡选择。
当机器人开始“思考”,人类更需清醒。我们不应只问“它能做什么”,而要追问“我们想让它成为什么”。技术的终点不是替代人类,而是拓展人类的能力边界。
真正的智能革命,不在于机器像人,而在于人与机器共同进化。








